SimVP: A Simpler Path to Better Video Prediction
Background and Motivation
In layman’s terms, video prediction can be thought of as extending a video or generating a video from an image. In today’s times, video prediction has emerged as a crucial task with applications spanning different categories, including but not limited to climate change forecasting, human motion prediction, and traffic flow analysis.
In the current landscape of such video prediction approaches, researchers have been developing increasingly sophisticated models using state-of-the-art techniques, including recurrent neural networks (RNNs) and vision transformers (ViTs). These approaches, however, rely on elaborate architectures, which require a lot of computation and data to train on.
SimVP tries to challenge this trend towards more and more complex architecture by posing a fundamental question: “Is there a simple method that can perform comparably well?”. This question forms the foundation of the research done by the authors of this paper.
The Problem of Video Prediction
We already defined video prediction in a rudimentary way. Now, let’s define it more formally.
Video prediction aims to infer the future frames based on the previously observed frame(s). Given a video sequence containing the past frames, the goal is to predict the future sequence containing the upcoming frames.
This requires finding a mapping function
Model Architecture
SimVP introduces a straightforward yet effective architecture consisting of three main components:
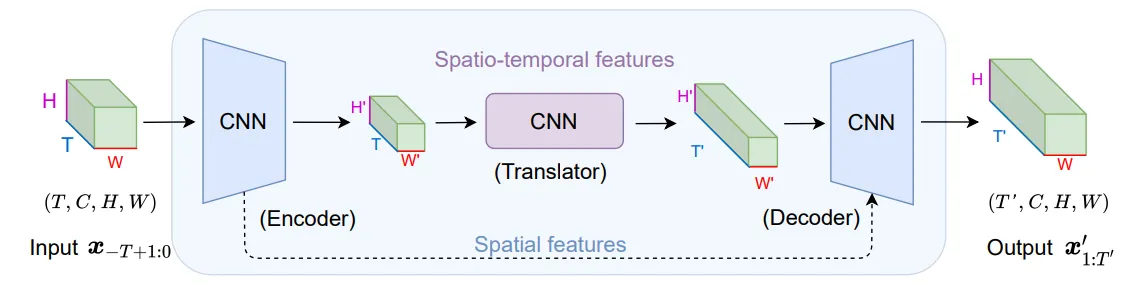
Overview of the Entire Model Architecture
Spatial Encoder
The encoder extracts high-dimensional spatial features from past frames and encodes them into a low-dimensional latent space.
It has layers of ConvNormReLU blocks (Conv2d + LayerNorm + LeakyReLU) stacked on top of each other that convolute on channels of the input.
Spatiotemporal Translator
The translator functions as the core of the model, learning both spatial dependencies and temporal variations from the latent representations.
It employs inception modules to learn temporal convolution, i.e., convoluting channels on . The inception module consists of a bottleneck Conv2d with a kernel followed by parallel GroupConv2d operators.
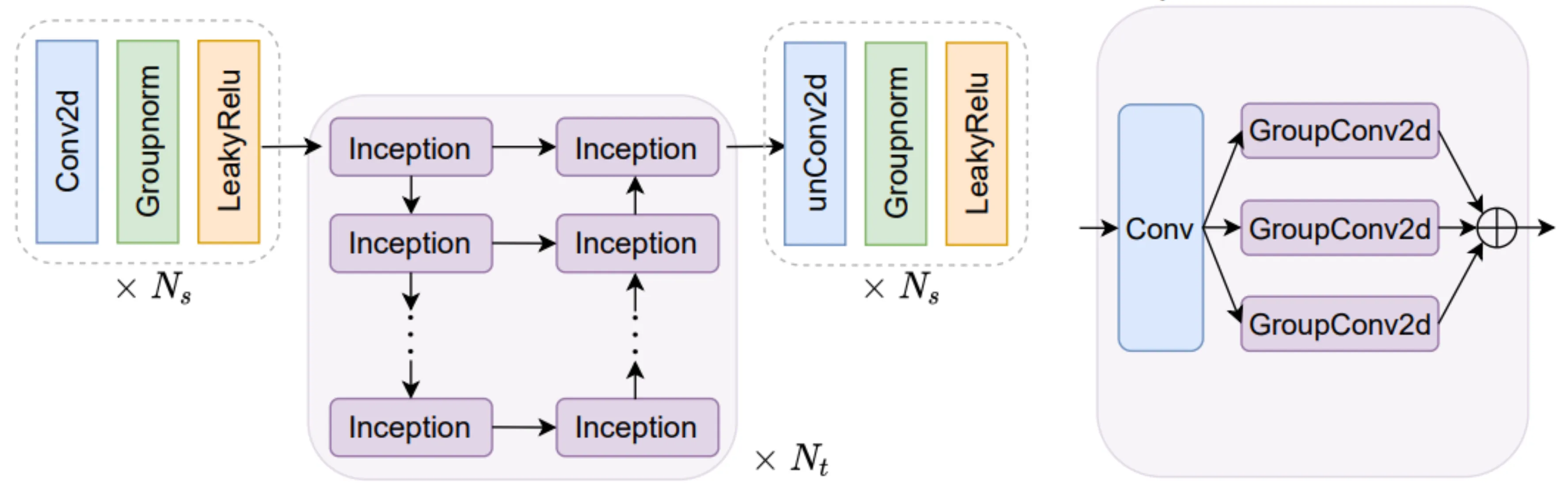
Translator Architecture
Spatial Decoder
The decoder decodes the processed latent representation into the predicted future frame.
It again utilizes unConvNormReLU blocks (ConvTranspose2d + GroupNorm + LeakyReLU) to reconstruct the video frames, which would convolute on channels of .
Putting It All Together
The design of this model disentangles the learning of the spatiotemporal features by first extracting the spatial information through the encoder, then integrating this knowledge to learn the temporal evolution via the translator before finally reconstructing the predicted frames via the decoder.
It does the entire process without using any advanced modules such as RNN, LSTM, or transformer and does not introduce any complex training strategies It just uses vanilla CNNs and MSE loss!
Feature Processing Approach
What makes SimVP’s approach unique is how it processes features across different modules.
- In the spatial encoder and decoder, input tensors are reshaped to treat each frame as a single sample, focusing on single-frame level features regardless of temporal variations.
- In the translator, hidden representations from the spatial encoder are reshaped to stack multi-frame level features along the time axis, enabling the model to capture intrinsic temporal evolutions within the sequential data.
Which Translators Should be Chosen?
The paper explores different types of architectures for the translator, which is the most important part of the model. They try out 3 different architectures, namely RNN, CNN and a Transformer.
For RNN, the currently state-of-the-art PhyDNet and CrevNet were chosen. As suggested in PhyDNet, the PhyCell, a novel time module was used for temporal modelling. As to CrevNet, a normalizing flow autoencoder + ST-LSTM was used.
For Transformers, a model from Video Swin Transformer and Latent Video Transformer was used which certain modifications in the implementation details without changing the core algorithm.
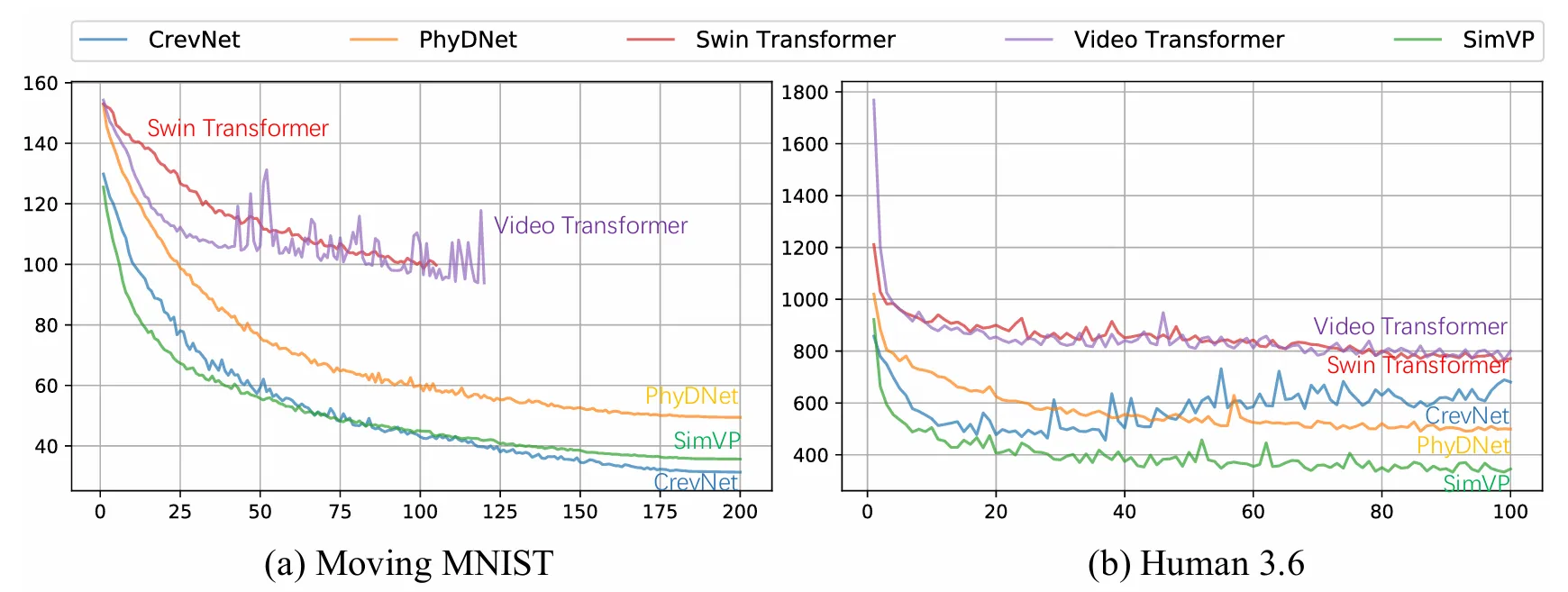
Comparison between different translator architectures
Results
As is evident from the above graphs, the CNN and RNN achieve state-of-the-art performance under limited computation resources. However RNN converges faster than CNN in the long run if the capacity of the model is sufficient. CNN training is however more robust and does not fluctuate drastically at large learning rate.
An important point to note is that the Transformer has no advantage in the SimVP framework when restricted under similar resource consumption which is expected as the Transformer architecture is known to require a lot of computational resources.
Performance & Benchmarks
SimVP has demonstrated exceptional performance across various benchmark datasets such as Moving MNIST, KTH and Human3.6 which is a human pose dataset focusing on “walking” scenarios. SimVP outperforms several RNN-based approaches, including ConvLSTM, PredRNN, CausalLSTM, MIM, E3D-LSTM and PhyDNet.
What’s particularly impressive is that SimVP achieves these results without requiring auxiliary inputs or elaborate architectures and sophisticated training strategies that are common among competing approaches.
| Moving MNIST | TrafficBG | Human 3.6 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| MSE ↓ | MAE ↓ | SSIM ↑ | MSE × 100 ↓ | MAE ↓ | SSIM ↑ | MSE / 10 ↓ | MAE / 100 ↓ | SSIM ↑ | |
| ConvLSTM | 103.3 | 182.9 | 0.707 | 48.5 | 17.7 | 0.978 | 50.4 | 18.9 | 0.776 |
| PredRNN | 56.8 | 126.1 | 0.867 | 46.4 | 17.1 | 0.971 | 48.4 | 18.9 | 0.781 |
| CausalLSTM | 46.5 | 106.8 | 0.898 | 44.8 | 16.9 | 0.977 | 45.8 | 17.2 | 0.851 |
| MIM | 44.2 | 101.1 | 0.910 | 42.9 | 16.6 | 0.971 | 42.9 | 17.8 | 0.790 |
| E3D-LSTM | 41.3 | 86.4 | 0.910 | 43.2 | 16.9 | 0.979 | 46.4 | 16.6 | 0.869 |
| PhyDNet | 24.4 | 70.3 | 0.947 | 41.9 | 16.2 | 0.982 | 36.9 | 16.2 | 0.901 |
| SimVP | 23.8 | 68.9 | 0.948 | 41.4 | 16.2 | 0.982 | 31.6 | 15.1 | 0.904 |
Many more experiments were done by the authors of the paper, which showed that, although there is room for improvement, the simple SimVP also generalizes well across different datasets and can extend very well to different predictive lengths.